記者/施嫚祺
Google於11日公布音訊分離技術(Audio-Visual Speech Separation)的研究結果,提出深度學習視聽模型,將影片中所有人物的聲音分離成獨立音軌,此技術未來可應用於視訊、多人會議或者辯論的政治節目,當閱聽眾點選影片中特定人物,就能夠只聽到他的聲音。
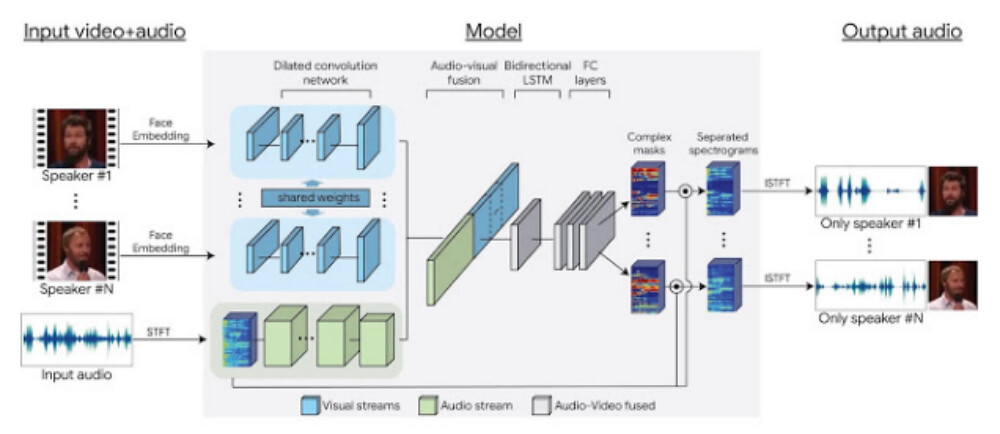
■ Google發表音訊分離技術的深度學習視聽模型。(截圖自/Google Research Blog)
Google此研究透過視覺訊號分離音訊,提高語音判讀的準確度,強化影片中特定人聲音量,甚至能夠去除影音中的雜音,只留下清晰的音軌播放,此技術應用了「雞尾酒會效應」,即人類有很強的聽力選擇能力,在音訊複雜的環境中,可僅將注意力集中在某個人的聲音,而忽略其他的雜音,因此人們可以在吵雜中進行談話。
研發過程中,Google蒐集10萬支Youtube上演講的影片,僅擷取演講人的聲音,保留約2千小時的影音內容訓練模型,並透過蒐集這些數據建立「合成雞尾酒派對」(Synthetic cocktail parties)資料庫,藉由人工智慧分離音訊的功能以訓練模型。
Google開發團隊表示,將音訊分離後有助於提升語音辨識系統,以自動生成字幕,故當閱聽眾在觀看Youtube的影片時,按下右下方的CC按鈕,即可呈現更準確的字幕,而未來適用範圍相當廣泛,將繼續研究如何應用在其他產品上。