資料來源:builtin
真的具備智慧?還是只具備部分智慧?
當前正是觀察人工智慧帶來影響的大好時機:2022 年在人工智慧在深度學習方面取得相當進展,特別是在生成模型(Generative Model)方面。然而,隨著深度學習模型功能的增加,相關的質疑與不斷增加。從一方面來看,ChatGPT 和 DALL-E 等高級模型帶來令人驚艷的成果,讓模型進行推理的能力又更上一層樓,但在另一方面,他們經常犯下錯誤,證明他們缺乏人類所擁有的一些基本智力要素,這種「高級智能」卻又犯下「常態錯誤」的模式正讓產官學界思考,人工智慧到底哪一個部分需要調整,對人類的衝擊是比想像中的快或慢?有專業機構認為,不同人工智慧模型未來將產生不同的「個性」,在不同情境產生思考偏誤,另一派則認為,無論是何種模型,將最終具備通用人工智慧(Artificial General Intelligence),但不存在個性問題。
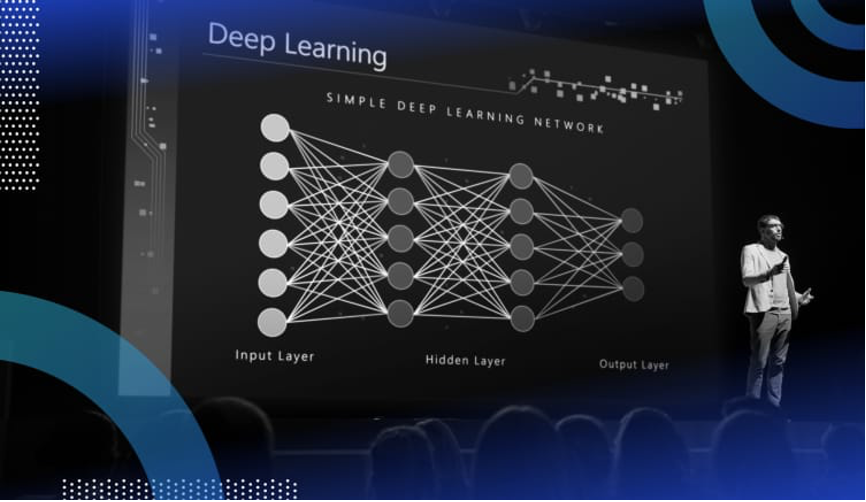
(深度學習當前成為人工智慧熱點。資料來源:IBM)
深度學習當前面臨的幾大挑戰
目前推進深度學習的方法仰賴增加訓練數據、建立更大的模型、更有效的coding等方法,但不少專家指出,這樣只會加速這些深度學習模型所犯的錯誤。這個缺陷在 ChatGPT 中相當明顯,它可以生成正確且一致性的語法、但缺乏邏輯與不符合事實現狀的文本。不少使用過該會議的演講者提供此類缺陷的案例,例如大型語言模型無法根據長度對句子進行排序,在簡單的邏輯問題上會犯嚴重錯誤,以及做出錯誤和不一致的陳述。主要原因在於模型並未加入語言和思想、對常識的一般認知、人類是什麼這類問題,甚至是任何其他幻想與想像力。整體而言,我們可以歸納出數個缺陷,第一為推理與答案互斥,大型語言模型無法推理基本事物,例如將對象放入模型中,模型可以回答問題,但使用者可能無法指望得到答案;第二是事實性不足,模型不能透過倒入他們新的事實來逐步更新,這些模型通常需要接受再訓練以吸收新知識,因此顯得笨拙。
深度學習平台需要時間來發現模式、分析數據並得出可應用於現實世界的結論。AI 平台正在不斷發展以滿足不斷成長的模型訓練需求,因此這些平台將與數據分析一樣成熟,而不是需要數週的學習時間才能開始工作。資料集的規模不斷擴大,深度學習模型不斷變得更加資源密集——它們需要更多的處理能力來預測、驗證和重新校準數千次,而圖形處理單元 (GPU) 正在不斷進步以應對這些強烈的需求。同時,深度學習工作負載越來越容器化,。這些技術幫助公司在 MLOps 中具有隔離、無限可擴展性、可移植性和動態行為。人工智慧基礎設施的管理現在更加自動化和業務友好。以容器化為核心,Kubernetes 能協助雲原生 MLOps 與其他更成熟的技術,使得公司在整合 Kubernetes 時能在更加靈活的雲端環境中展開 AI 各種專案部署。
當前專家對於未來人工智慧的期望
簡單來說,我們所謂的「常識」對人工智慧而言相當困難,常識對於人類來說幾乎是無需思考,而對於機器來說卻很難,因為顯而易見的事情永遠人們不會說出來並視為理所當然,而且常識性的事情沒有普遍的真理,有些隱性的現象,比如人際關係、社會互動、企業文化等,常識是透過感官經驗獲得的,並且這些知識存儲在感知和運動系統中,模型可能無法透過「感知」這些情境來做出適合的推演。部分業界專家也提出觀點與期望,Elemental Cognition的創始人、IBM Watson 的前成員大衛·費魯奇 (David Ferrucci) 認為,如果人類無法讓機器「解釋為什麼它們會產生它們正在產生的輸出」,我們就無法實現我們對 AI 普及化的的願景,費魯奇的公司正在設計一種架構,該架構可以解釋其推論和因果模型,這是當前 AI 中缺少的兩個功能。
AI 科學家 Ben Goertzel 則指出「目前主導當前商業 AI 領域的深度神經網路不會在構建真正的 AGI取得太大進展。」Goertzel 以創造 AGI 一詞而聞名,他認為以事實檢查核措施強化 GPT-3 等現有模型不會解決深度學習面臨的問題,也不會使它們能夠像人類思維一樣思考。瑞士人工智慧實驗室 IDSIA 的科學主任兼現代深度學習技術的先驅之一 Jürgen Schmidhuber 表示,當前人工智慧的許多問題已在過去幾十年中被解決。Schmidhuber 建議解決這些問題是運算成本的問題,未來人類需持續建立深度學習系統,進行元學習並找到新的更好的學習演算法。